How write operation done in HDFS?
HDFS follows Write once Read many model, so we can't edit files which are already present in HDFS.
Syntax to write data in HDFS:
hdfs dfs -put <local/file/path> <HDFS/location/where file needs to write>
exmple:
hdfs dfs -put /home/prajjwal/file1.txt /landing_location/
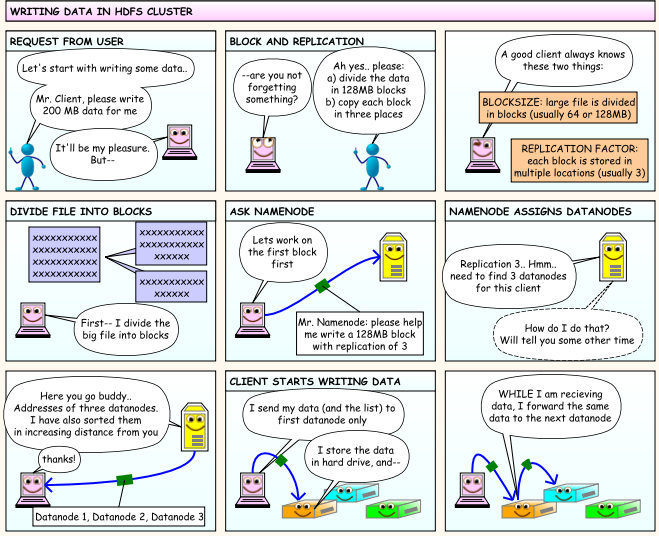
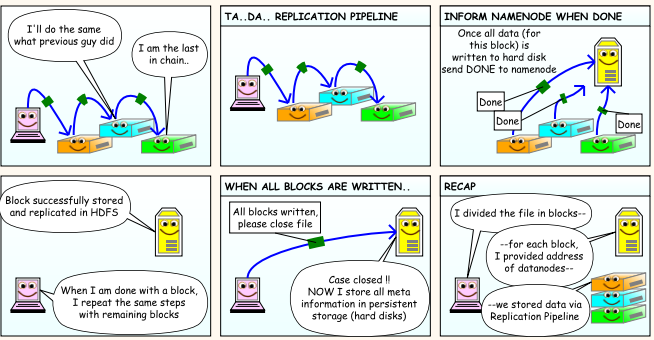
To write a file in HDFS, a client needs to interact with master i.e. namenode (master). Namenode provides the address of the datanodes (slaves) on which client will start writing the data. Client can directly write data on the datanodes, now datanode will create data write pipeline.
The first DataNode will copy the block to another datanode, which intern copy it to the third datanode. Once it creates the replicas of blocks, it sends back the acknowledgment.
We can understand with the help of below cartoon diagram.
Thanks All.
Comments
Post a Comment